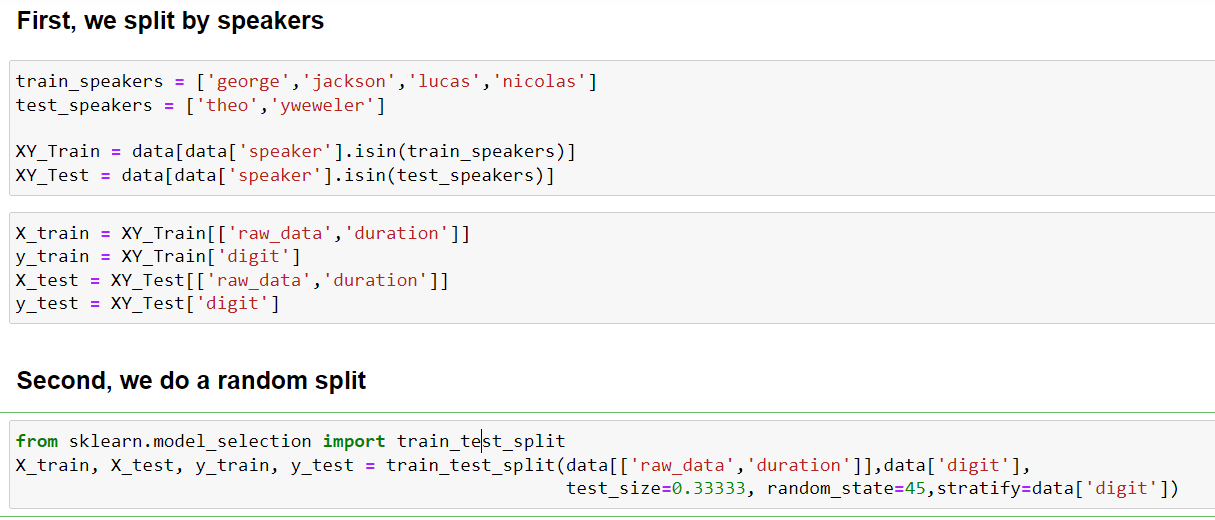
Different training testing set split stragedy: randomly vs by speakers
Published:
We first download audio MNIST (digits) data from here. This is a balanced dataset in terms of labels/digits and speakers, with 6 male speakers and each person has 500 recordings for digits, 50 recordings per digits per person. Each digits have then 50 x 6 = 300 files. We here describe the result of different training test fold split stragedy.
- random split: we split training and test data by random split
- Split based on speakers: this senario is closer to real-world case applications where the data from the same speaker goes either training fold or test fold but not both.
Result of two different train test fold split stragedies
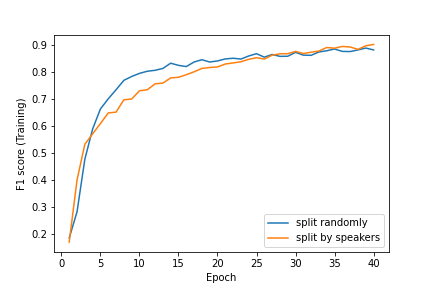
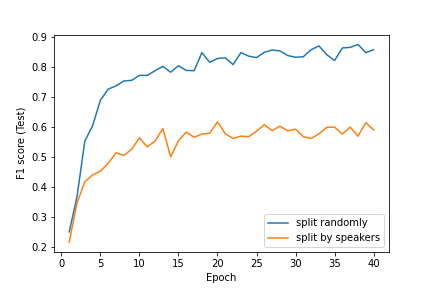
We plot the performance metric F1 score (micro) for multi-class classification, which is commonly used when all classes are balanced. For imbalanced problems, different weighted scheme for F1 scores can be found here. We use 2/3 data for training and 2/3 data for testing. The max length was set to 0.8 seconds to preserve most data.
Here is the training performance (Top) and testing performance (Bottom). Training performances for two splitting scheme are relatively similar, especially around stable performance with increasing number of epochs. However, the testing performance for split for speakers suffers much more compared to random splitting. For split randomly, stable testing performance is around 0.85 whereas for split by speakers, the stable test performance is around 0.6 for the same number of total 40 epochs.
The main implementation for these two methods is as follows: